
Can AI be trusted for Adverse Effects Case Processing from Regulatory Authorities?.
AI on Adverse Effects is usually trained on annotated data. Making it resource and capital intensive. What if we benchmark with models trained on source documents instead?


Adverse Effects Case Processing (AECP) is the set of activities for monitoring and scouting drug reactions, expected and unexpected effects. It represents a huge portion of a Pharmacovigilance (PV) process. The potential automation of AECP is rather a fascinating problem, especially when considering that it represents the strongest cost driver within PV.
In this field, AI has already been proven to be able to solve AECP. Though the models used by the industry rely upon direct annotation of source documents. In most cases that means that the data is manually labeled. A process that is rather time consuming and a burden for smaller life science companies that do not have neither the time nor the resources.
What if we could train AI on source documents instead of an annotated dataset?
That is training AI models directly on the documents tailored towards safety monitoring.
This question has been addressed with a scientific experiment: Schmider J, Kumar K, LaForest C, Swankoski B, Naim K, Caubel PM. Innovation in Pharmacovigilance: Use of Artificial Intelligence in Adverse Event Case Processing. Clin Pharmacol Ther. 2019 Apr;105(4):954-961. doi: 10.1002/cpt.1255. Epub 2018 Dec 11. PMID: 30303528; PMCID: PMC6590385.
The experiment was conducted by benchmarking 3 AI Vendor’s towards Pfizer Artificial Intelligence Center of Excellence (Pfizer AI CoE). The 3 models were trained on source documents and safety databases rather than annotated data.
Validity & Accuracy
In order to benchmark the AI models, the experiment relied upon validating the data, and consequently measuring the accuracy towards Pfizer baseline.
Validity of the output was decided upon the presence of 4 elements, as required by Regulatory Authorities for ease of submissions towards FDA/EMA:
- Suspected drug reaction
- Putative Causal Drug
- Patient
- Reporter
The measurement of the output was taken by standard industry measurements used also for benchmarking search engines relevancy:

Benchmarking
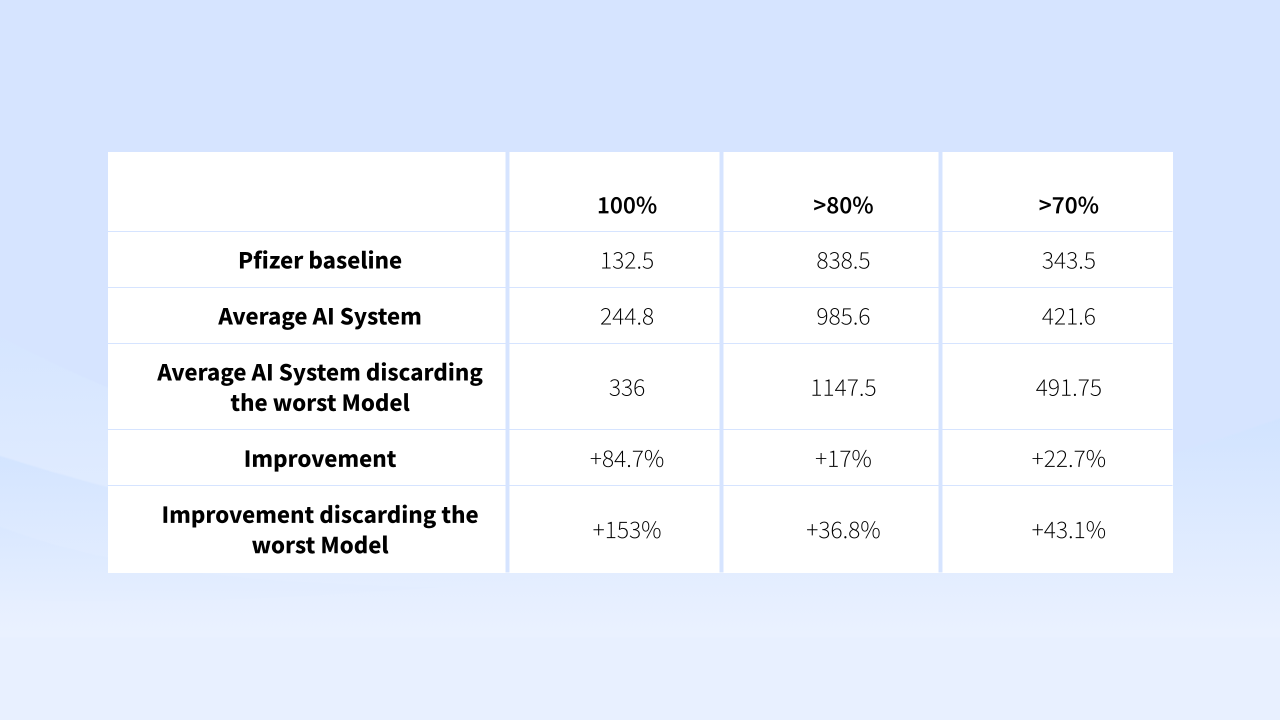
The average F1-score of Pfizer AI CoE was F1-0.66, while the 3 vendors performed on average F1-0.68.
When then discarding the worst performing model, the improved to F1-0.73. This represents the overall accuracy of precision and recall of the model.
Accuracy on average improved for +84.7% with cases processes 80-100% completeness. Meaning that 8-9 out of 9 entity types were predicted accurately. While when discarding the worst performing model, accuracy improved to +153%.
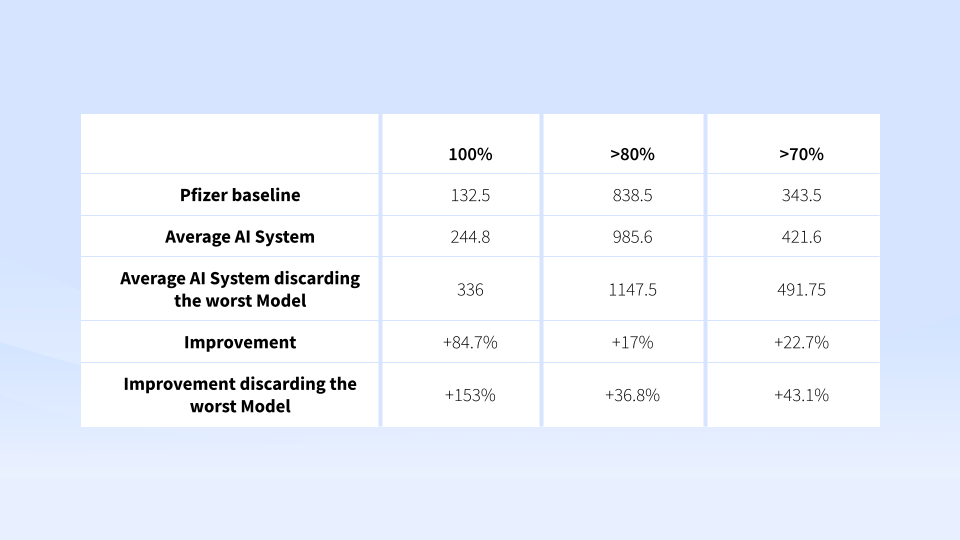
Validity levels instead varied a lot from vendor to vendor. But one of them was able to perform +2% better than its baseline counterpart at identifying the 4 elements.
Conclusion
The experiment showed that you can replace your current solutions with AI trained upon source documents, and get similar results. In general the accuracy was higher.
PapersHive internal algorithms for signal detection are based on the same premise. Providing a high accuracy at both search and discovery level.
Would you like to speed up your Adverse Effects Case Processing and Signal Detection? Thanks to our AI trained on source documents, you can achieve high accuracy while maintaining the costs at hand. Set up a free trial and contact us.

Everything starts with search.
With a smart suite of search tools to help you find the information you need, when you need it. Enhance your Search Experience with PapersHive Today!
Contact Us