
💰 Handling duplicates is costly. But how much? What can you do about it?.
When performing a Systematic Literature Review, 56.9% of the initial data could be duplicated. This could cost a bioresearch and pharma company from €224 for an employee to €1,000 per contractor for each screening activity. And well beyond €10k when performing SLR. Unless you have it automated.


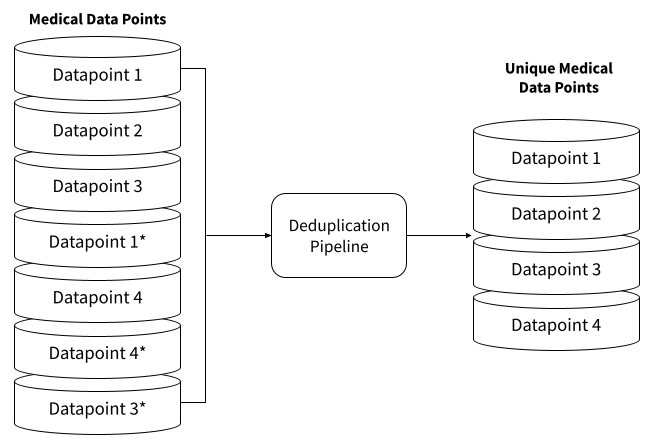
While duplication might seem a standard and for certain aspects even a trivial problem, it is further from that. It involves several aspects such as signal detection, threshold, steps and even a multi-document mapping procedure when considering full-text search.
🛑 Scenario: your usual problem.
You are digging into a new area that you don’t know much about. You browse PubMed, Cochrane, MEDLINE, Web of Science, Scopus, PapersHive and other databases with medical information. You have now a few hundreds papers in your collection when performing a screening activity, while you have thousands of medical data points when performing a systematic literature review.
You usually would end up in one of these cases:
- You used the same database for the browsing activity, for example PubMed. This boils down to a 16% average of duplicates in your final collection with non over 3,500 results in total. This is mainly because even browsing on different search terms, results might be similar. Such as searching for “painkiller” and “morphine”.
- You used several databases. We still didn’t identify an average, but we registered a peak as high as 56.9% in the amount of verified duplicates in a Systematic Review going from 64,627 medical data points to 27,850.
Even with quick methodologies of 15 seconds per result to assess if it is a duplicate or not, the task of removing duplicates manually would range from 14.5 hours for a Screening Activity, and 11 days for a Systematic Literature Review.
2️⃣ How to remove duplicates
The problem of duplicates is far from trivial. When considering publications, many present the same title even though they are different ones, and some errata corrige could introduce changes in title or abstract while still pointing at the same publication.
As an extra consideration, false negatives (remaining duplicates in manually deduplicated datasets) are preferred to false positives (removing unique references unintentionally).
This is the main reason why at PapersHive we split it into two groups and you should probably do the same. The certain group, as it is most certainly, contains a duplicate with 99% accuracy. And the maybe-group that might contain it and it is up to the professional to decide.
The set of signals you should be using to detect 99% of duplicates:
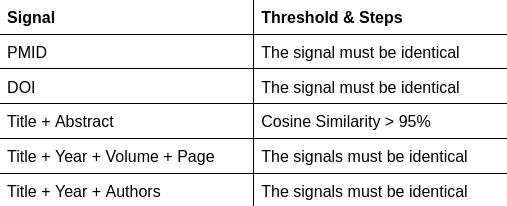
A second set of signals for identify probable duplicates:

The search problem
This creates a huge problem for search engines and their users. As a starter when searching, users tend to want different results. This implies that the system should be able to detect and remove the duplicate before ingesting it into its index (database).
Especially when showing a short list in forms of top-10-results a search engine shouldn’t show same results, nor results too similar one with the other.
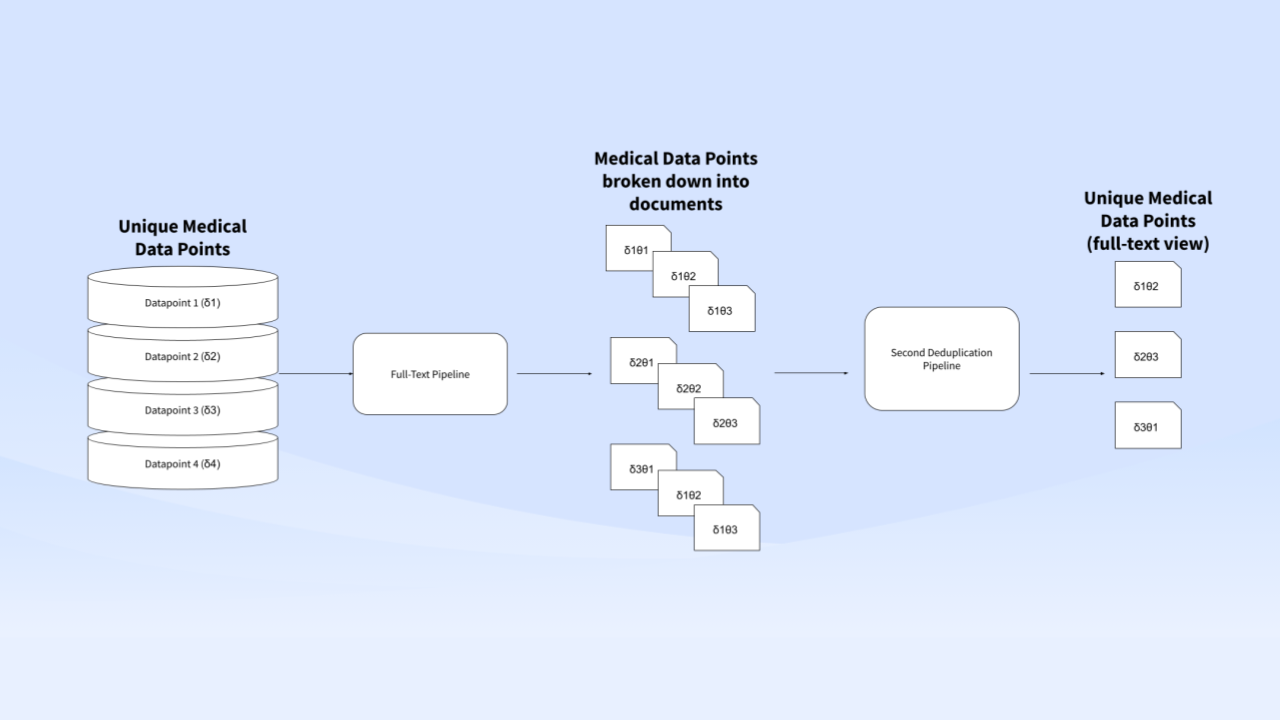
When then considering full-text search engines such as PapersHive, the problem becomes even more nested. A single medical dataset “δ” produces several documents “θ”, but the results should still only include unique data points:
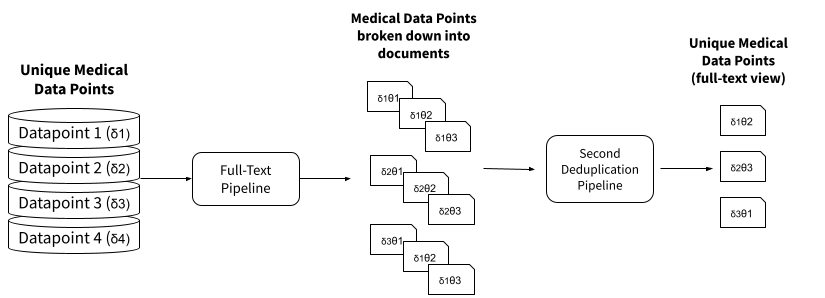
The advantage in using a search engine or reference manager behind the curtains, is that screening activities and SLR could remove up to 99% of duplicates saving a minimum of 14.5h for quick-screening.
🚀 Conclusions
When considering the costs of a Screening Activity, the automated removal of duplicates alone would save you €224 and up to €1,000 when considering a contractor. While performing a full-on systematic literature review from an institution, the non-automated removal could cost up to up to €14k.

Everything starts with search.
With a smart suite of search tools to help you find the information you need, when you need it. Enhance your Search Experience with PapersHive Today!
Contact Us