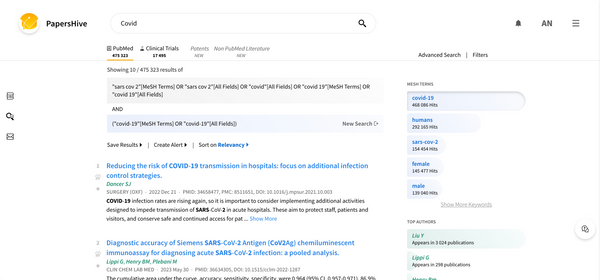
New Feature New! More intuitive Search Explanation to guide the user It has been noted that the Search Explanation is often missed and the addition of Keywords is misunderstood. Therefore PapersHive is introducing a new design - to highlight the functionality of diving deeper, and to carefully guide the user to better understanding what is happening.
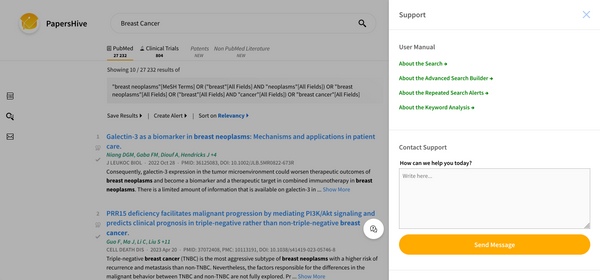
New Feature New! Help Button for submitting Feedback, or other Questions PapersHive introduces a help button for submitting feedback, reporting bugs or asking questions. The goal is for PapersHive members to always have an easy access to support, and facilitate bug reporting.
Reports 🧑🔬 3,878 Chemicals benchmarked: PubMed vs PapersHive. Chemicals play a crucial role in relevancy: substances, drugs, compounds, toxins, molecules, etc. On PapersHive you can find +44% references with these searches.
Reports 8,943 MeSH terms ⚕️ benchmarked: PubMed vs PapersHive PapersHive finds on average 47% more hits than PubMed when it comes to MeSH searches.
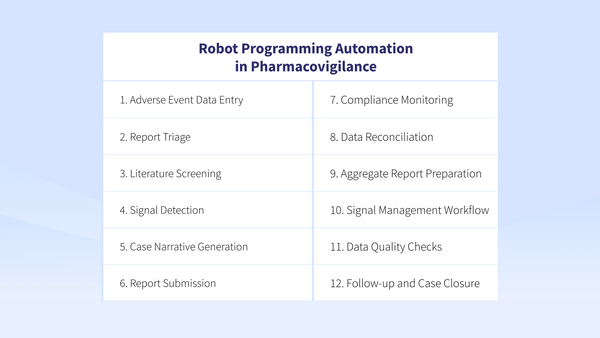
🚀 12 RPA scenarios for Pharmacovigilance 12 use cases for Robot Programming Automation in Pharmacovigilance that simplify the job-to-be done of your PV team. In perfect automation.
Reports 🔥 700+ Adverse Effects benchmarked: PubMed vs PapersHive PapersHive finds on average 66% more hits than PubMed when it comes to FAERS Adverse Effect. Just by leveraging full-text.
Reports 💊 Market Approved Drug: PubMed vs PapersHive PapersHive finds on average 71% more hits than PubMed when it comes to Market Approved Drugs by the FDA. Just by leveraging full-text.
Newsletter 🤖 Automate Pharmacovigilance monitoring on Literature Pharmacovigilance and in general signal detection over adverse effects can in part be automated through PubMed and MeSH search with 69% precision.
Newsletter Featured Make your PubMed searches 75% more Precise in 5 steps 1. Gather all references 2. From each get MeSH terms 3. Count occurrences 4. Focus on the low 10th percentile 5. Extrapolate the top-3 results
Discussion Does PubMed search full-text? 📑 No, PubMed does not search in full-text search. If you want to search full-text you should go to PubMed Central or PapersHive.
Discussion Why Pharmacovigilance should use comprehensive search over Google 🔍 In pharmacovigilance and drug related activities, your focus should be on comprehensiveness and inclusion criteria rather than a relevant top ten of results that cannot be explained.
Case Study How Cinclus Pharma ensured searchability of references with PapersHive for GERD Cinclus Pharma started using PapersHive centralizing search (PubMed and Clinical Trials), reference management and AI analytics in a end-to-end solution.
Discussion 🚀 3 proven methods to leverage clinical-market insights 1. Filter by industry and academia 2. Filter by phases. 3. Filter by MeSH.
Discussion 😣 6 most common errors in Literature Search Strategies affecting recall. 1. Incorrect use of Boolean operators 2. Lack of parenthesis 3. Lack of morphological variations 4. Missing MeSH terms 5. Non-proper MeSH tags 6. Miss synonyms
Case Study Norwin massively reduced time spent on searching literature with PapersHive Norwin Zuidema spent countless hours searching about specific topics, finding the most relevant literature, and stay up to date with trends. – I was delving into a new subject and reading lots of new literature, which was taking cumbersome amounts of time to filter what was relevant and what was not.
Discussion 🥊 Google Scholar vs PubMed When performing a medical literature review you should use PubMed or PapersHive. Use Google Scholar for lookup searches and quick explorations.
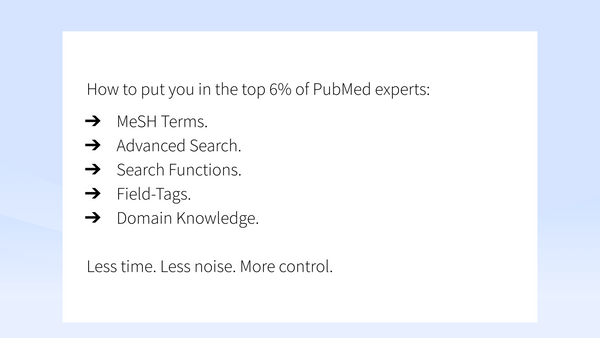
Discussion 🤯 How to put you in the top 6% of PubMed experts A study analyzed PubMed’s log data and identified differences between expert and non expert users. To become better at PubMed you should start using MeSH terms, Advanced Search, use the search functions, field-tags and domain knowledge. These alone would put you to the top 6%.
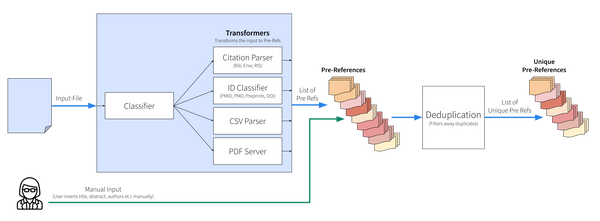
Discussion ⬇️ How a Reference Manager works, Part I: Importing The first part in building a Reference Manager is the Import. This phase focuses on taking a user input and transforming it into a list of pre-references.
Discussion 🔎 The Best Medical Search Engine According to Your Need There is no such thing as the best Medical Search Engine. Though we have started noticing patterns when it comes to which area or need each medical professional has. And the best engine associated to it!
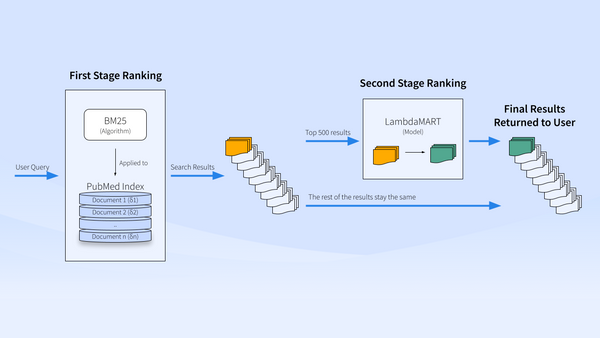
Discussion 🤔 How does PubMed work behind the curtains? PubMed left TF-IDF and started using BestMatch: a two-stages ranking system based on BM25 to gather the first batch of documents, and a Learning-to-Rank model to re-rank the top 500.
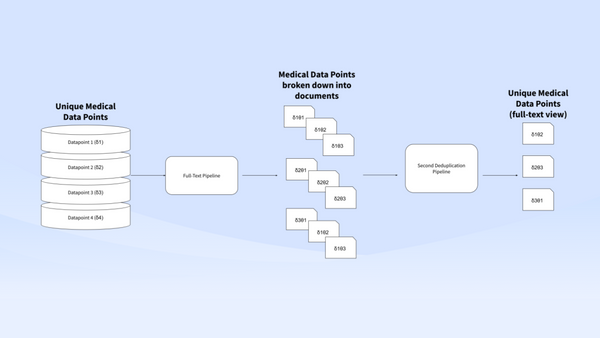
Discussion 💰 Handling duplicates is costly. But how much? What can you do about it? When performing a Systematic Literature Review, 56.9% of the initial data could be duplicated. This could cost a bioresearch and pharma company from €224 for an employee to €1,000 per contractor for each screening activity. And well beyond €10k when performing SLR. Unless you have it automated.
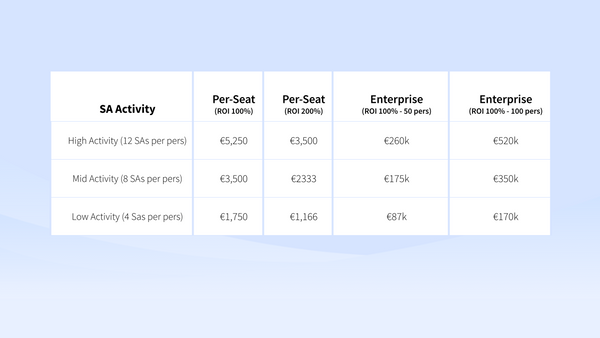
Discussion 💵 When is it convenient to buy automation in the Drug-to-Market Journey? You might wonder when is automation useful in your Life Science pipeline for automated screening. In a price-per-seat model, that is €875 divided by the wanted ROI. In an Enterprise model it is up to the number of scientists.
Case Study Featured How Lab Consultancy Group went from days of research to minutes without losing in quality Lab Consultancy Group (LCG) is a British company providing scientific consulting. They used to spend days and weeks gathering medical data points, with PapersHive the time spent shrunk to hours.
Discussion Can AI be trusted for Adverse Effects Case Processing from Regulatory Authorities? AI on Adverse Effects is usually trained on annotated data. Making it resource and capital intensive. What if we benchmark with models trained on source documents instead?
Discussion 4 steps you could easily automate in your Pharmacovigilance and Monitoring processes Your team can shrink a week of manual work in just a few hours. By iterating with 7 of our core customers, we identified 4 steps that could easily automated when performing Pharmacovigilance and Clinical / Monitoring processes thanks to AI and RPA.